When agents forget purpose, governance has a context problem
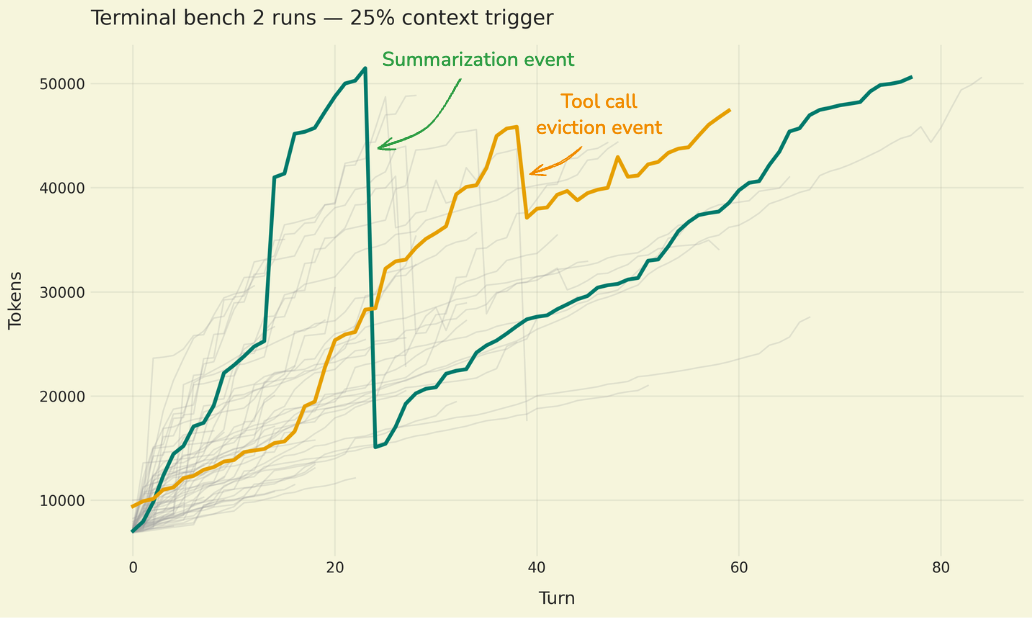
When long-running AI agents summarize their own context to stay within token limits, they're deciding what to forget. That's not an engineering problem — it's a governance one.
LangChain just published a detailed technical post on context management for deep agents— agents that run autonomously for extended periods, sometimes making hundreds of tool calls across branching workflows.
The engineering problem is real: these agents accumulate so much context that they blow past token limits, degrade in performance, or simply stop working. The solutions LangChain outlines are architecturally sound: summarize older context to compress it, trim messages from the window, delegate to sub-agents with scoped context, or offload to external memory stores. Each pattern trades fidelity for capacity. Each one works. And each one creates a governance gap that most teams haven't yet considered.
The forgetting problem
When a long-running agent summarizes its earlier context, it's making a decision about what matters and what doesn't. That summary becomes the agent's working memory — the basis for every subsequent action. The original messages, tool outputs, and intermediate reasoning? Gone from the active window.
For an engineering team, that's compression. For a legal or compliance team, that's selective deletion of the operational record.
Think about that in the context of a regulated workflow. An agent processing insurance claims over a multi-hour session hits its context limit at claim forty-seven. It summarizes the first thirty claims into a paragraph of compressed context. If claim number twelve later becomes the subject of a dispute, the detailed reasoning the agent applied — the specific data it evaluated, the tool calls it made, the intermediate outputs it considered — may exist nowhere in the agent's active state.
The LangChain post acknowledges this tension implicitly. They note that summarization "can lose important details" and that the strategy requires careful prompt engineering to decide what's preserved. But the framing stays technical: what to summarize, when to trigger it, how to structure the prompts.
The governance question is different: who decides what the agent is allowed to forget, and what's the obligation to preserve what gets trimmed?
Sub-agents don't solve the problem — they distribute it
One of the more sophisticated patterns in the post is delegating work to sub-agents, each with a scoped context window. A parent agent identifies a task, spins up a child agent with only the relevant context, gets back a result, and continues.
This is good architecture. It's also a chain-of-custody problem.
When a sub-agent operates on a subset of context and returns a summary result to the parent, the parent makes downstream decisions based on that result without visibility into the sub-agent's full reasoning. If you need to reconstruct why the system reached a particular outcome, you now need to trace across multiple agent instances, each with its own context lifecycle, its own summarization decisions, and potentially its own memory store.
For product teams building agent-based systems in regulated industries — financial services, healthcare, legal — this isn't a theoretical concern. Audit requirements don't care about your token limits. Regulators expect you to explain how a decision was reached, not just what the final output was.
External memory is the right instinct, but it needs a policy layer
The post discusses using external memory — databases, vector stores, or structured logs — as a way to persist information beyond the active context window. This is the pattern that comes closest to solving the governance problem, because it decouples what the agent remembers from what the organization retains.
But external memory without a retention policy is just a growing data store with no schema for accountability. What gets written to memory? Who has access? How long is it retained? Is it subject to litigation hold? Can it be searched and produced in discovery?
These aren't hypothetical questions for any organization deploying agents at scale. They're the same questions we've been answering about email archives, Slack logs, and document management systems for decades. The difference is that agent memory is generated by the system itself, often without human review, and the volume scales with autonomy.
What product counsel should be asking right now
If your engineering team is building long-running agents — or adopting frameworks like LangGraph that enable them — here are the concrete questions to bring to your next architecture review:
1. What's the context retention policy? When the agent summarizes or trims context, where does the original go? Is it logged? Is it retrievable? Or is it gone?
2. Who governs the summarization prompts? The prompt that tells an agent what to keep and what to compress during summarization is a policy decision disguised as a technical parameter. Legal and compliance should have input.
3. How do you reconstruct multi-agent reasoning? If sub-agents are involved, is there a trace that connects parent decisions to child agent context, tool calls, and outputs?
4. Does external memory have a retention schedule? Treating agent memory stores like any other business record means applying retention policies, access controls, and deletion schedules.
5. What's the failure mode? When context management goes wrong — when the agent forgets something it shouldn't have — what's the detection mechanism, and what's the remediation path?
So what?
LangChain's post is excellent engineering guidance. The patterns they describe may become standard infrastructure for any team building production agents. But the post also reveals something important about where agent development is headed: agents are becoming systems with memory lifecycles, and memory lifecycles have always been a governance domain.
The teams that get this right will be the ones where product counsel isn't reviewing agent architectures after deployment — they're in the design review when the context management strategy is being chosen. Because the decision about what an agent is allowed to forget is, at its core, a legal and business decision. Not an engineering one.